1)パーソナルゲノムサービスの始まり
ヒトのゲノムは1991年のヒトゲノム計画より解析が始まり,2000年にドラフト配列が作成され,2003年にヒトの全ゲノム解析完了が宣言された1).ヒトゲノム配列が解読されたことによって,ゲノム情報を活用した研究が可能になり,その成果が多数報告されてきた.HapMapプロジェクトや,1000人ゲノムプロジェクトなどを含む,国内外で大規模な分子疫学コホート研究も多数行われ,疾病や生活習慣などの環境因子とゲノム情報の関係を解明する研究が進められており,遺伝的個人差が疾患リスクや体質,性格などを規定するという研究結果が多数報告されてきている2).一方で,遺伝子解析の技術そのものも著しく発展している.DNAチップの技術を用いることにより,多数の遺伝子のCNV(copy number variation)解析やゲノムワイドに一塩基多型(single nucleotide polymorphism:SNP)を一度に解析できるゲノムワイド関連解析(genome wide association study:GWAS)を容易に行うことが可能となった.さらには次世代シーケンサの開発によって,1000ドル以下の安価で高速かつ大量にヒトの全ゲノム情報を得ることが可能となってきたことから,海外では10年以上前から一般個人向けにゲノム解析を提供し,個人が自らのゲノム情報を持つというサービスが登場した[パーソナルゲノムサービス(personal genome service:PGS)].日本では,一般消費者向けの遺伝子解析サービスはいくつか存在したものの,2014年の1月にゲノムワイドな解析手法を個人向けに提供するサービスを当社が初めて開始した.このように,技術的な発展の背景から,PGSが誕生し,さらにヒトゲノムを解析することで得られる情報をどのように研究へ活かし社会で実用化するかについて注目されている状況にあるといえる.こうした個人のゲノム情報はすでに医療分野においては創薬や個別化治療に活用されており,栄養・食品分野などの医療以外の領域においても応用への期待が高まっている.
2)パーソナルゲノムサービスが生命科学研究にもたらすメリット
PGSのメリットを捉える際に,最新の研究知見を社会に浸透させていくことで,個人の疾病予防や健康維持の推進に貢献する役割を担っているが,生命の仕組みを解き明かす研究においても大きなイノベーションを起こしている.
生命科学研究におけるビッグデータ取得の重要性を考えるときに,生命科学研究における研究者としての役割は今後変化し始めると考えられる.たとえば,ゲノムなどあらゆる生体情報の取得が容易になり,情報ビッグデータ時代に突入しているという状況では,情報が加速度的に蓄積されていき,データに基づく仮説構築や意思決定がなされていくようになるからである.これまでは知識と経験のある専門家が,知見に基づいた仮説を立てるしか方法がなかったのが,大規模な生命分子情報の取得が容易に可能となった時代では,大規模なデータを取得してから自動的に,あるいは統計的にデータから仮説を構築するという流れが起こっている.こうしてデータに基づく仮説を構築して研究を進めるアプローチを取り入れ,予想もしていなかった新しい発見が次々と生み出されている.つまり,これまで研究者の役割は,「知識に基づく仮設構築とその検証のサイクルを回すこと」だったのが,今後は「情報をうまく取得しながらいかに価値と独自性があることに活用できるか」という役割へとシフトしている.そのため,大規模にデータを取得することの必要性がこれまで以上に増している.
大規模なデータを生かしたゲノム研究自体はすでに世界中で数多く行われており,それに関するデータも蓄積されている.従来のバイオバンクにゲノム情報の収集が加わることで,ゲノム・オミクス個別化医療,創薬の情報基盤となっている.疾患型のバイオバンクや健常人型バイオバンクでは,前向きコホートとして健常人のゲノム情報と環境情報を集めて追跡するコホートが行われている.国内では東北メディカルメガバンクやバイオバンクジャパンなどが行われており,また遺伝子変異と表現型が紐づいたデータベースとしては,GWAS catalog, OMIM, dbGAPなどが存在する.
しかし,それでも多くの疾患や体質などの表現型に関する遺伝子多型データベースはまだ整備されておらず,特に栄養・食品分野など医療以外の領域において表現型と遺伝子の関係が未解明なものが多い.特定の疾患や研究領域にしか遺伝子多型との関連の研究報告がなされていないのは,研究がなされた結果明らかにできなかったのではなく,そもそも研究自体が数多くない点にある.ゲノムの解析コストだけでなく,GWAS研究を行おうとすると膨大な被験者数を集める必要があり,膨大なコストが必要となる点が一つのハードルとなっている.当社ではPGSを推進することによってゲノムのビッグデータへのアクセスを可能とし,生活習慣や既往歴などのアンケート情報も組み合わせて活用することで,ゲノムデータのさらなる解析により新規の関連を見つける研究を行っている.個人が自身の遺伝子多型の情報を持つ時代になりつつあることを考慮すると,個別化医療や健康維持を考える上で遺伝子多型とさまざまな表現型の関連性の研究を加速させることが不可欠であり,そこへのPGSの果たす役割は非常に大きいと考えられる.また,厚生労働省が実施した「ゲノム情報を用いた医療等の実用化タスクフォース」において,DTC遺伝子検査は「十分な知見の蓄積が進むことで国民の生活習慣改善,健康増進を牽引する可能性がある」と述べられており3),栄養・食品分野においても適切なゲノム活用により国民の健康増進に貢献することが期待されている.
1)PGSの仕組みと研究への活用方法
DTC遺伝子検査は,個人が採取した頬粘膜や唾液等の検体試料から,SNP等の遺伝的個人差に関する情報を個人に直接提供する民間サービスである.DTC遺伝子検査では採血が不要であり,インターネット等を介して検査キットを購入することができ,個人が手軽に受けることができるため,ここ数年,日本国内においても利用者は増加している.また当社では,サービスによって蓄積されたゲノムデータについて,あらかじめサービス利用者の同意を得た上で個人情報とは切り離し,情報の取り扱いや利用目的について倫理審査委員会で承認を得た上で,ゲノムデータの研究を行っており,これまでに30以上の研究機関と共同研究を進めている.
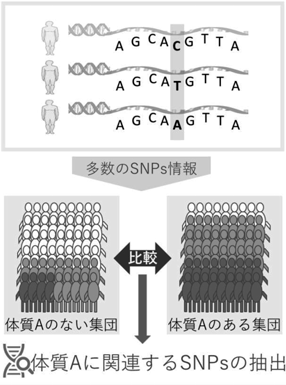
当社ではインターネットを活用しているため,一般のバイオバンク等と比較してユーザーへのアクセスが容易であり,追加アンケートを実施することで前向きな研究デザインの設計が可能である点,また一部の地域に限定されるのではなく全国47都道府県のユーザーにアクセス可能な点が特徴となる.研究デザインに沿ったアンケート設問を設計し,ユーザーに追加調査を実施して得られたアンケートデータと,ゲノムデータを合わせて解析を行うことで,GWAS研究を行っている(図1).
2)栄養・食品分野におけるパーソナルゲノム研究の事例
i)研究背景
前述のように,すでにさまざまな疾患発症リスクに関連するSNPマーカーが同定されている.また,食品成分が疾患発症リスクに与える影響には,遺伝的個人差が影響することがわかっている.最も研究されている遺伝子多型の一つに,葉酸代謝に関係する疾患リスクのSNPであるMTHFR C677Tの例があげられる.この遺伝子型がTT型の人は,葉酸が不足しがちになり,その結果,血中のホモシステイン濃度の上昇を介して血管疾患や認知症などさまざまな疾患のリスクが高まることが明らかとなっている4).したがってTT型の遺伝子多型の人は疾患予防のために,葉酸を多めに摂取することが望ましく,これは実際に個別化栄養指導として現場で実践されている(香川の稿を参照)5).他にも,閉経後の女性でカルシウム摂取量が少ないと骨密度が減りやすい遺伝子多型6)や,コーヒー摂取によって高血圧症になりやすい遺伝子型7)などが報告されている.食品成分の代謝・生体応答に関する個人差の例としては,カフェイン過敏症やアルコール代謝に関わるSNPが報告されており8, 9),遺伝子型を調べることで個人の適正なアルコールやカフェイン摂取量が推測できる.嗜好品の過剰摂取による健康被害がしばしば報告されているが,遺伝子検査により個人が適切な摂取量目安を知り行動を変えることで,その被害予防に貢献する可能性がある.また,乳糖耐性,グルテン感受性,ピーナッツやエビなどの食品アレルギーに関するSNPなども報告されており10–13),摂取を控えるべき食品成分や発症リスク予測,予防および治療戦略に関する情報を提供できる可能性がある.食嗜好や味覚に関するSNPも複数見つかっており,苦味や塩味を感じやすいかどうかや,糖質を好んで摂取する傾向にあるかどうかなどとの関連も報告されている14–16).
このように,疾患リスクに関連する食品とSNPの相互作用について知見が集まり始めている.しかし,多くは欧米系集団における研究結果であることから,日本人集団で同じように知見を適用できるかは不明であることもあり,食による疾患の個別化予防の実現のためには,さらに膨大なデータの蓄積や研究が不可欠である.
当社と東京大学の共同研究により実施した,PGSを活用した栄養・食品分野の研究を二つ紹介する.上述の個別化栄養・食品に疾患予防やQOL(quality of life)の向上を目指し,Webアンケートにより取得した食品の摂取頻度と,それに関係する遺伝子多型の探索を実施するGWAS研究を行った.具体的には,ユーザーの日常生活におけるコーヒーの摂取頻度17),甘味の嗜好性18)について,それぞれGWASを実施した.
ii)研究例1:コーヒー摂取量に関する遺伝子多型
食品因子の中で,コーヒーの摂取量とSNPとの関連については比較的研究が進んでおり19, 20),欧米ではすでにGWASにより同定されたSNPsがコーヒーの健康増進メカニズム解明の糸口となる可能性が示唆されている.一方で,コーヒーの摂取量に関して日本人集団を対象とした大規模ゲノム解析の研究報告はなかったため,本研究では日本人を対象としたGWASによりコーヒー摂取量と関連する新規関連SNPを探索すること目的とした.
上述のDTC遺伝子検査サービスを通じてインターネット経由で募集した日本在住の健康な男女約1万2千人の唾液試料からDNAを抽出した後,SNPアレイを用いてゲノムワイド(約30万SNPs)に遺伝子型タイピングを行った.また,コーヒーの摂取量に関するアンケートを行い,1か月あたりのコーヒー摂取量を7段階(ほとんど飲まない,週2杯以下,週3~4杯,週5~6杯,毎日1~2杯,毎日3~4杯,毎日5杯以上)に分け,回答を得た.遺伝子型タイピングデータから,pLINKを用いてGWASを行った.
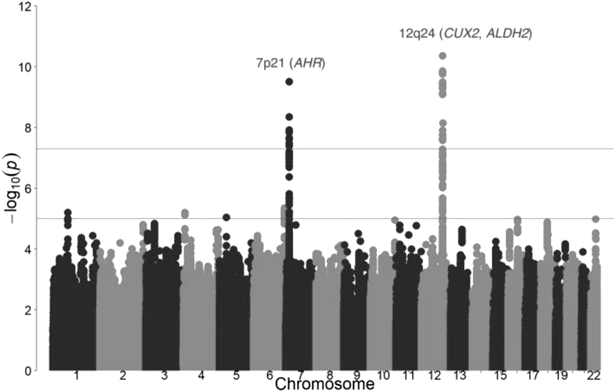
その結果,GWASによりゲノムワイドな有意水準(p値<5.0×10−8)を満たす遺伝子座を2か所同定した.このうち1か所は,ヒト7番染色体上の7p21領域上に存在し(rs10252701;P=1.0×10−14),カフェインの代謝やコーヒー摂取量と関連することが明らかになっているaryl-hydrocarbon receptor(AHR)遺伝子の上流に位置していた(図2).欧米人を対象とした研究でもAHR遺伝子近傍の座位が同定されており,本研究によりコーヒー摂取量とAHR遺伝子との関係が裏づけられた.一方,もう1か所,欧米人集団では発見されていなかった,ヒト12番染色体の12q24領域上の座位(rs79105258;P=9.5×10−15)が同定された(図2).この座位はCUX2遺伝子上に存在していたが,12q24領域には代謝に関わる遺伝子が集中して存在しており,また連鎖不平衡が強くみられるため,コーヒー摂取量と直接関係する遺伝子座を特定するにはさらなる研究が必要となる.
さらに,調整因子を加えた解析では,コーヒー摂取量と7q21領域および12q24領域の関連にはBMIや飲酒,喫煙を介していないことが明らかとなった.また,コーヒー摂取量と関連している座位について詳しく解析すると,どちらの座位にも年齢差はみられなかったが,12q24領域上の座位とコーヒー摂取量との関連には男女差があり,女性よりも男性の方が強く相関することが明らかとなった.二つの座位について,同じくアンケートにより取得したBMI,総コレステロール値,中性脂肪値,HbA1c値を比べてみると,コーヒーを多く摂取する傾向にあるグループでBMIと中性脂肪が有意に低いことがわかった(表1).
表1 コーヒー摂取量関連SNPsの多面的効果 | rs10252701 | rs79105258 |
|---|
| Beta | SE (Beta) | P | Beta | SE (Beta) | P |
|---|
| BMI | 0.021 | 0.049 | 0.67 | −0.188 | 0.053 | 3.5×10−4 |
| 総コレステロール値 | −0.690 | 0.635 | 0.28 | 0.120 | 0.674 | 0.86 |
| 中性脂肪値 | −0.186 | 0.888 | 0.83 | −2.488 | 0.948 | 8.7×10−3 |
| HbA1c | 0.015 | 0.011 | 0.17 | −0.004 | 0.0012 | 0.71 |
| BMI:体格指数,SE:標準誤差,年齢・性別・地域で補正済み. |
本研究により,インターネットによるゲノムコホート研究でも食品因子に関わるSNP候補を抽出可能であることが示された.また,ヒトゲノム上のコーヒー摂取量に関連する領域を同定したことで,コーヒーの持つ健康増進作用の生理学的機構の解明に寄与することが期待される.
iii)研究例2:甘味の嗜好性に関する遺伝子多型
二つ目の研究として,甘味の嗜好性に関するGWAS研究を紹介する18).甘味への嗜好は,ヒトに生理的に備わった能力である一方,糖類の過剰摂取は肥満,糖尿病,代謝異常等を引き起こす恐れがある.そのため,甘味嗜好性のメカニズムを解明することは,生活習慣病予防においても重要と考えられている.一方,甘味への嗜好は地域によって異なること,また遺伝的な要因が関わることが既存の研究で判明しており,欧米の研究グループから甘味への嗜好の個人差の約50%は遺伝要因が占めるという報告がある21, 22).また,他の欧米集団を対象とした研究からも,甘味に限らずさまざまな味覚への嗜好性に影響するゲノムの中のSNPが判明している23–26).しかし,SNPは地域による分布差が大きいため,国外の研究結果が必ずしも日本人に当てはまるとは限らない.また,これまでにアジア系集団を対象にしたゲノムワイドな研究は報告されていなかった.
上述と同様に,インターネットを介した日本人約1万2千人のゲノム情報と,甘味への嗜好を「大嫌い」「嫌い」「普通」「好き」「大好き」の5段階に分け,Webアンケートで取得した結果情報を用いてGWASを実施した.
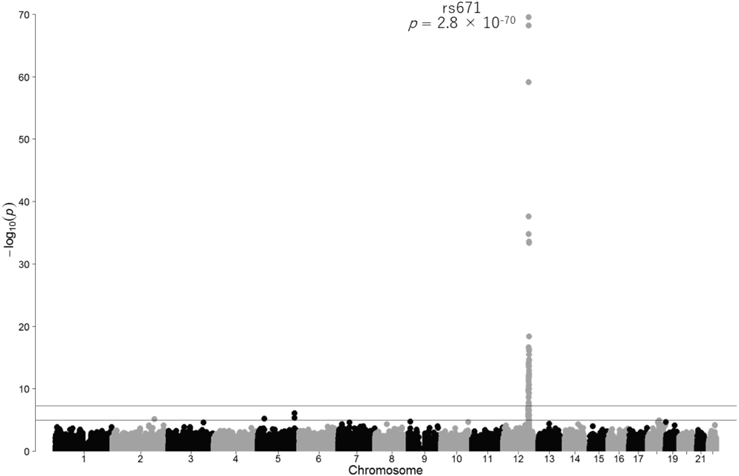
その結果,ヒト12番染色体上の12q24領域にある遺伝子多型rs671(P=2.8×10−70)が甘味への嗜好性に強く関連していることが明らかとなった(図3).関連が明らかになったrs671は日本人を含む東アジア系の集団に特有であり,それ以外の地域ではほとんど多型がみられないSNPである.また,アルコール代謝に関わるアルデヒドデヒドロゲナーゼ2遺伝子(ALDH2)上に存在し,アルコールへの耐性と関係することが知られている.解析の結果,お酒に弱い遺伝子型は,甘味への嗜好性と正の関連があることが明らかとなった.
さらにrs671と甘味への嗜好性との関連性をアルコール摂取量・アルコール摂取頻度で調整し再解析すると,効果が減弱化したことから,rs671と甘味への嗜好性の関連はアルコールの摂取を介していることが明らかになった.しかし,アルコール摂取により調整した後もrs671と甘味への嗜好性の関連は残っていたため,アルコール摂取を介さない関連があることも示唆された.アジア集団以外を主な対象とした先行研究では,甘味への嗜好が強いほどアルコール消費が多い傾向が報告されていたが,本結果では甘味への嗜好が強いほどアルコール消費が少ないという異なる傾向がみられた.さらに,rs671と甘味への嗜好性との関連を,男性と女性に分けてそれぞれ解析した結果,男性でより強い関連が認められた.
本研究によって,日本人集団において,お酒に弱いタイプの遺伝子多型を持つ飲酒習慣が少ない人では,甘味への嗜好が強い傾向があることが示唆された.本研究成果は味覚の嗜好性に関する遺伝的背景を解明する一助となる他,糖尿病予防や肥満治療などにも応用できることが期待される.
また,ヒトゲノムと食品や食習慣の関連についてはいまだ不明な点が多く,特に日本人集団における研究は少ないため,今後他の食品についても研究が必要であると考えられる.
iv)PGSを活用した「インターネット・コホート」の可能性
国内でPGSを活用した当社の研究発表例について紹介したが,本研究によってインターネットを通じた問診とパーソナルゲノムデータを用いることが,栄養・食品分野への応用可能性を裏づけることができた.上記に述べた今回の研究では,これまでに欧米で先行している栄養・食品分野におけるヒトゲノム研究による結果を再現し,またアジア系集団に特有の新規の結果も得ることができた.
PGSによるインターネットを活用したコホートには従来に比べて多くの可能性があると考える.それは多様な研究デザインが可能である点だ.たとえばGWAS研究では,どの地域の人を対象にするのか,アンケート情報などの環境要因に関する附帯情報をいつ取得するのか,1人あたりどのアンケートをとるのか,などの要素である.インターネットを使うコホート研究のメリットとして,これらの三つの要素の制限から解放し選択肢を広げるという大きなメリットがある.たとえば,従来のコホートは地域限定であることが多いが,インターネットの活用により全国から,また全世界からもデータを取得可能である.また,インターネットを通じて検査の項目やデータを後から追加したり,定期的に情報取得したりすることが容易であるため,時系列のデータを集積することができる.従来のコホート研究は,明らかにしたい結論を導くために必要な調査項目を事前に確定し,後からそれを変更したり追加したりすることは難しいことが多かったが,その制限を取り除くことが可能となる.こうした三つの要素における制限を打ち破る研究デザインの自由度の高さが,インターネット・コホートの大きな可能性となる.どのように研究デザインを設計してそれらのデータを分析していくかの自由度が高くなる分,いかに膨大なデータを価値化できるかは,研究者としての力量が問われることである.
4. 生命科学のビッグデータを活用した先に待っている未来とは
我々が未来について考えるときに,まずは過去から含めた全体の流れを捉えることが重要である.ゲノムデータについての流れとしては,1950年代にDNAが発見され,2003年にはヒトゲノム配列が解読された.その後,ゲノムの解析技術が飛躍的に発展し,データ取得の時間とコストが急速に下がったことでデータ取得が容易になった.ゲノムの機能が解読されてきたことで,ゲノムだけではなく,それに関係するエピゲノムやRNAやタンパク質,代謝産物など,セントラルドグマのさまざまな生命現象が明かされてきた.これらの研究分野は対象としている分子の語尾にomicsをつけて,それぞれgenomics, transcriptomics, proteomics, metabolomicsなどと呼ばれるが,現在はセントラルドグマの各ステージにおいてビッグデータの取得が容易となってきた.
それでは今後どうなるかというと,セントラルドグマの複雑性を考慮すると,やはりmRNA・タンパク質・代謝物など複数のステージでの多層的なビッグデータを統合的に捉えていくことは必至の流れであると考える.今後これらの情報は体系的かつ大規模なデータの取得が可能になっていくため,10年以内には,生体の法則性に対する理解が飛躍的に深まるようになる.生体の法則性が包括的に明らかにされていくと,その法則性を再現,予測,変化(制御)することが可能となる.つまり,ヒトの健康状態を分子レベルで再現したり,データドリブンの疾病の超早期発見(予測),生体に異常が見つかった場合それを変化させ制御することが選択肢として当たり前になると考える.さまざまなハードルはあるが,今後ビッグデータが生命科学や医療を急激に発展させていく過程のまだ途中であり,その先には大きな可能性が広がっている.
引用文献References
1) Schmutz, J., Wheeler, J., Grimwood, J., Dickson, M., Yang, J., Caoile, C., Bajorek, E., Black, S., Chan, Y.M., Denys, M., et al. (2004) Quality assessment of the human genome sequence. Nature, 429, 365–368.
2) MacArthur, J., Bowler, E., Cerezo, M., Gil, L., Hall, P., Hastings, E., Junkins, H., McMahon, A., Milano, A., Morales, J., et al. (2017) The new NHGRI-EBI Catalog of published genome-wide association studies (GWAS Catalog). Nucleic Acids Res., 45(D1), D896–D901.
3) 第4回ゲノム医療等実用化推進TF(http://www.mhlw.go.jp/file/05-Shingikai-10601000-Daijinkanboukouseikagakuka-Kouseikagakuka/160127_s4.pdf).
4) Hiraoka, M. & Kagawa, Y. (2017) Genetic polymorphisms and folate status. Congenit. Anom. (Kyoto), 57, 142–149.
5) Hiraokai, M. & Kagawa, Y. (2015). The Vitamin Society of Japan, 89, 59–64.
6) Stathopoulou, M.G., Dedoussis, G.V.Z., Trovas, G., Theodoraki, E.V., Katsalira, A., Dontas, I.A., Hammond, N., Deloukas, P., & Lyritis, G.P. (2011) The role of vitamin D receptor gene polymorphisms in the bone mineral density of Greek postmenopausal women with low calcium intake. J. Nutr. Biochem., 22, 752–757.
7) Palatini, P., Ceolotto, G., Ragazzo, F., Dorigatti, F., Saladini, F., Papparella, I., Mos, L., Zanata, G., & Santonastaso, M. (2009) CYP1A2 genotype modifies the association between coffee intake and the risk of hypertension. J. Hypertens., 27, 1594–1601.
8) Childs, E., Hohoff, C., Deckert, J., Xu, K., Badner, J., & de Wit, H. (2008) Association between ADORA2A and DRD2 polymorphisms and caffeine-induced anxiety. Neuropsychopharmacology, 33, 2791–2800.
9) Li, D., Zhao, H., & Gelernter, J. (2012) Strong protective effect of the aldehyde dehydrogenase gene (ALDH2) 504lys (*2) allele against alcoholism and alcohol-induced medical diseases in Asians. Hum. Genet., 131, 725–737.
10) Saadah, O.I., Shaik, N.A., Banaganapalli, B., Salama, M.A., Al-Harthi, S.E., Wang, J., Shawoosh, H.A., Alghamdi, S.A., Bin-Taleb, Y.Y., Alhussaini, B.H., et al. (2015) Replication of GWAS Coding SNPs Implicates MMEL1 as a Potential Susceptibility Locus among Saudi Arabian Celiac Disease Patients. Dis. Markers, 2015, 351673.
11) Lewinsky, R.H., Jensen, T.G.K., Møller, J., Stensballe, A., Olsen, J., & Troelsen, J.T. (2005) T-13910 DNA variant associated with lactase persistence interacts with Oct-1 and stimulates lactase promoter activity in vitro. Hum. Mol. Genet., 14, 3945–3953.
12) Hong, X., Hao, K., Ladd-Acosta, C., Hansen, K.D., Tsai, H.J., Liu, X., Xu, X., Thornton, T.A., Caruso, D., Keet, C.A., et al. (2015) Genome-wide association study identifies peanut allergy-specific loci and evidence of epigenetic mediation in US children. Nat. Commun., 6, 6304.
13) Khor, S.S., Morino, R., Nakazono, K., Kamitsuji, S., Akita, M., Kawajiri, M., Yamasaki, T., Kami, A., Hoshi, Y., Tada, A., et al. (2018) Genome-wide association study of self-reported food reactions in Japanese identifies shrimp and peach specific loci in the HLA-DR/DQ gene region. Sci. Rep., 8, 1069.
14) Dias, A.G., Rousseau, D., Duizer, L., Cockburn, M., Chiu, W., Nielsen, D., & El-Sohemy, A. (2013) Genetic variation in putative salt taste receptors and salt taste perception in humans. Chem. Senses, 38, 137–145.
15) Drayna, D. (2005) Human taste genetics. Annu. Rev. Genomics Hum. Genet., 6, 217–235.
16) Eny, K.M., Wolever, T.M.S., Fontaine-Bisson, B., & El-Sohemy, A. (2008) Genetic variant in the glucose transporter type 2 is associated with higher intakes of sugars in two distinct populations. Physiol. Genomics, 33, 355–360.
17) Jia, H., Nogawa, S., Kawafune, K., Hachiya, T., Takahashi, S., Igarashi, M., Saito, K., & Kato, H. (2019) GWAS of habitual coffee consumption reveals a sex difference in the genetic effect of the 12q24 locus in the Japanese population. BMC Genet., 20, 61.
18) Kawafune K., Hachiya T., Nogawa S., Takahashi S., Jia H., Saito K., Kato H. (2020) J Hum Genet., Online ahead of print.
19) Pirastu, N., Kooyman, M., Robino, A., van der Spek, A., Navarini, L., Amin, N., Karssen, L.C., Van Duijn, C.M., & Gasparini, P. (2016) Non-additive genome-wide association scan reveals a new gene associated with habitual coffee consumption. Sci. Rep., 6, 31590.
20) Lee, J.K., Kim, K., Ahn, Y., Yang, M., & Lee, J.E. (2015) Habitual coffee intake, genetic polymorphisms, and type 2 diabetes. Eur. J. Endocrinol., 172, 595–601.
21) Keskitalo, K., Knaapila, A., Kallela, M., Palotie, A., Wessman, M., Sammalisto, S., Peltonen, L., Tuorila, H., & Perola, M. (2007) Sweet taste preferences are partly genetically determined: identification of a trait locus on chromosome 16. Am. J. Clin. Nutr., 86, 55–63.
22) Keskitalo, K., Tuorila, H., Spector, T.D., Cherkas, L.F., Knaapila, A., Silventoinen, K., & Perola, M. (2007) Same genetic components underlie different measures of sweet taste preference. Am. J. Clin. Nutr., 86, 1663–1669.
23) Fushan, A.A., Simons, C.T., Slack, J.P., & Drayna, D. (2010) Association between common variation in genes encoding sweet taste signaling components and human sucrose perception. Chem. Senses, 35, 579–592.
24) Eny, K.M., Wolever, T.M.S., Fontaine-Bisson, B., & El-Sohemy, A. (2008) Genetic variant in the glucose transporter type 2 is associated with higher intakes of sugars in two distinct populations. Physiol. Genomics, 33, 355–360.
25) Eny, K.M., Corey, P.N., & El-Sohemy, A. (2009). Dopamine D2 Receptor Genotype (C957T) and Habitual Consumption of Sugars in a Free-Living Population of Men and Women, J Nutr Nutr, 2, 235–242.
26) Chu, A.Y., Workalemahu, T., Paynter, N.P., Rose, L.M., Giulianini, F., Tanaka, T., Ngwa, J.S., Qi, Q., Curhan, G.C., Rimm, E.B., et al.; CHARGE Nutrition Working Group; DietGen Consortium. (2013) Novel locus including FGF21 is associated with dietary macronutrient intake. Hum. Mol. Genet., 22, 1895–1902.